Webサイトを運営していると Google Search Console に登録するサイトマップを準備する必要がありますよね。
Wordpress などではプラグインで簡単に作ることができますが、それ以外だと自分で用意しないといけません。
自動生成してくれるサービスもありますが、サイトマップを更新する際には手間が掛かります。
PHP を使ったスクリプトも数多くありますが、どうやらファイルを検索して一覧にするというものばかりでした。
これでは動的に生成されるページがサイトマップに登録されませんので、自作することにしました。
コードの詳細はまた別途記事にしたいと思います。
とりあえず今回はコードの公開までとします。
サイトマップとは?
ここでいうサイトマップとは、主に Googlebot などの検索エンジンにサイト内にどんなページがあるのかを伝える役目があります。
これにより各ページがクロールされやすくなり SEO 対策としても有効です。
ちなみに Google のヘルプページには以下のように説明されます。
サイトマップとは、サイト上のページや動画などのファイルについての情報や、各ファイルの関係を伝えるファイルです。Google などの検索エンジンは、このファイルを読み込んで、より高度なクロールを行います。サイトマップはサイト内のどのファイルが重要かをクローラに伝えるだけでなく、重要なファイルについての貴重な情報(ページの最終更新日、ページの変更回数、すべての代替言語ページなど)も提供します。
つまり、サイトマップを Google Search Console に登録すると貴方のサイト内のページが漏れなくクロールしてもらえるようになりより検索に引っ掛かりやすくなる可能性が高くなります。
更新頻度や最終更新日時なども登録でき、次回クロールのタイミングを教えることにもなります。
また現在、各ページの優先度はクローラに使われていませんが今後は使われるかもしれません。
コードの紹介
では早速コードを紹介します。
作成したコード
ファイルのダウンロードはコチラ。
ZIP 圧縮しているので解凍して使用して下さい。
但し、本スクリプトを利用して生じた不具合や不利益等に関しては自己責任でお願いします。
再帰処理をしていますので、念のため無限ループに陥らないよう取得するページ数の上限は1,000ページとしています。
<?php
// 自分のサーバー以外からの呼び出しを弾く場合
/* こちらを有効にする場合はコメントアウトを削除
if(gethostbyaddr($_SERVER["REMOTE_ADDR"]) !== "サーバのホスト名"
|| gethostbyaddr($_SERVER["REMOTE_ADDR"]) !== "サーバのIPアドレス"){
exit("Bad Request!!");
}
*/
// 特定のキーをGETで渡して認証する場合
// 認証用のキーは任意の英数字
if($_GET["access_key"] !== "認証用のキー(ランダムな英数字の組み合わせを推奨)"){
exit("Bad Request!!");
}
//******************
// 設定
//******************
// トップページのURL
define("HOMEPAGE", "https://analogstd.com/");
// 出力するサイトマップのファイル名
// ※このPHPファイルから見た相対パスで指定
define("OUTPUT", "./sitemap.xml");
//******************
// 以下任意の設定
//******************
// サイトマップに登録しない拡張子
$ignore_types = Array(".jpg", ".png", ".gif", ".dat", ".log", ".jpeg");
// サイトマップに登録しないファイル名
$ignore_files = Array();
// サイトマップに登録しないディレクトリ名
$ignore_dirs = Array("/user/", "/dev/", "/admin/");
// 省略可能なファイル名の優先順位
// (サーバの設定と同じにしないと更新日時が違う可能性アリ)
$index_name = Array("index.html", "index.php", "index.cgi");
// 先頭に空の値を追加
array_unshift($index_name, "");
// 優先度の設定
// ディレクトリが深くなるごとの数値を決める (0.0~1.0)
// ※現時点ではGoogleはpriorityの値を使用していない (https://support.google.com/webmasters/answer/183668?hl=ja)
$priority_set = Array(1.0, 0.8, 0.5, 0.2);
// 更新頻度目安の設定
// 動的ページは随時(always)に設定
// always, hourly, daily, weekly, monthly, yearly, never
$freq_set = "weekly";
// 検索する階層の最大深さ
$max_depth = 10;
//******************
// サイト内のページを自動取得
//******************
// 実行開始時刻
// 現在時刻をUNIX時間で取得 (1970年1月1日0時0分0秒からの秒数)
$start_time = date("U");
// URLを保存する変数
$URLs = Array(md5(HOMEPAGE)."0" => [HOMEPAGE, false, 0]);
foreach($index_name as $index){
$modified_time = @filemtime(dirname(__FILE__). "/". $index);
if($modified_time){
$URLs[md5(HOMEPAGE)."0"][1] = date(DATE_W3C, $modified_time);
break;
}
}
// 登録しない拡張子とファイル名を連結する
$ignores = array_merge($ignore_types, $ignore_files);
// 無限ループ回避用
$infinity = 0;
// WebページをHTTP通信で取得してサイト内リンクを再帰しながら取得する
// 再帰は新しいURLが見付からなくなるまで続ける
function getSiteURLs($URL){
global $infinity;
// 無限ループに陥っても終了するようにクロールするページ数のMAXを設定する
// 最大ページ数ではないので注意すること (初期値 : 1000)
if($infinity < 1000){
$infinity++;
global $priority_set;
global $freq_set;
global $URLs;
global $ignores;
global $ignore_dirs;
global $index_name;
$html = @file_get_contents($URL);
$URL = explode("/", $URL);
if(isset($html) && $html !== 0){
preg_match_all('/<a [^>]*?href="([^"]+?)"[^>]*>/i', $html, $anchors);
foreach($anchors[1] as $a){
$a = preg_replace('/([^#]+)(#.*){0,1}/', '$1', $a);
$anchor = $a;
if(preg_match('/^\/(.*)$/', $a, $m)){
$anchor = HOMEPAGE. $m[1];
}
if(preg_match('/^\/\/(.*)$/', $a, $m)){
$anchor = 'https://'. $m[1];
}
$URL_buff = $URL;
if(strpos($anchor, "..") === 0){
$m = substr_count($anchor, "../") + 1;
array_splice($URL_buff, (0 - $m), $m);
$next = implode("/", $URL_buff). '/'. preg_replace("/^(\.\.\/)+/", "", $anchor);
} else if(strpos($anchor, ".") === 0){
$URL_buff[count($URL_buff)-1] = "";
$next = implode("/", $URL_buff). preg_replace("/^\.\//", "", $anchor);
} else if(strpos($anchor, HOMEPAGE) === 0){
$next = $anchor;
}
// 除外するファイルか確認する
$flag = true;
foreach($ignores as $ignore){
if(empty(end(explode($ignore, $next)))){
$flag = false;
}
}
// 除外するディレクトリか確認する
foreach($ignore_dirs as $ignore){
if(count(explode(HOMEPAGE.$ignore, $next)) > 1){
$flag = false;
}
}
// URLを保存する
if($flag){
if(!isset($URLs[md5($next)."0"][0])){
// 新しいURLの時は登録する
$URLs[md5($next)."0"] = [$next, false, count(explode("/", end(explode(HOMEPAGE, $next)))), implode('/', $URL)];
foreach($index_name as $index){
$modified_time = @filemtime(dirname(__FILE__). "/". end(explode(HOMEPAGE, $next)). $index);
if($modified_time){
$URLs[md5($next)."0"][1] = date(DATE_W3C, $modified_time);
break;
}
}
if(end(explode("/", $next)) === ""){
$URLs[md5($next)."0"][2]--;
}
getSiteURLs($next);
} else{
if($URLs[md5($next)."0"][0] === $next){
// 既に登録されていたら終了する
} else{
// 同じMD5値が登録されているか確認する
// 且つ、そのキーの配列が現在のURLでないことを確認する
$i = 1;
while(isset($URLs[md5($next).$i][0]) && $URLs[md5($next).$i][0] !== $next){
$i++;
}
if(!isset($URLs[md5($next).$i][0])){
$URLs[md5($next).$i] = [$next, false, count(explode("/", end(explode(HOMEPAGE, $next)))), implode('/', $URL)];
foreach($index_name as $index){
$modified_time = @filemtime(dirname(__FILE__). "/". end(explode(HOMEPAGE, $next)). $index);
if($modified_time){
$URLs[md5($next)."0"][1] = date(DATE_W3C, $modified_time);
break;
}
}
if(end(explode("/", $next)) === ""){
$URLs[md5($next)."0"][2]--;
}
getSiteURLs($next);
}
}
}
}
}
}
}
}
getSiteURLs(HOMEPAGE);
?>
<?php
//
//
//
?>
<?php echo '<?xml version="1.0" encoding="UTF-8"?>'."\n"; ?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<!-- Number of Detected Pages : <?php echo count($URLs); ?> -->
<!-- Processing time : <?php echo (date("U") - $start_time); ?>sec -->
<!-- Last Modified : <?php echo date(DATE_W3C); ?> -->
<?php foreach($URLs as $URL){ ?>
<url>
<loc><?php echo preg_replace("/&/", "&", $URL[0]); ?></loc>
<listed-on><?php echo preg_replace("/&/", "&", $URL[3]); ?></listed-on>
<lastmod><?php if($URL[1]){echo $URL[1];}else{echo date(DATE_W3C);} ?></lastmod>
<changefreq><?php if($URL[1]){echo $freq_set;}else{echo "always";} ?></changefreq>
<priority><?php if($URL[2] < count($priority_set)){echo $priority_set[$URL[2]];}else{echo end($priority_set);} ?></priority>
</url>
<?php } ?>
</urlset>
<?php
$site_map = "";
$site_map .= '<?xml version="1.0" encoding="UTF-8"?>'."\n";
$site_map .= '<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">'."\n";
$site_map .= '<!-- Number of Detected Pages : '.count($URLs).' -->'."\n";
$site_map .= '<!-- Processing time : '.(date("U") - $start_time).'sec -->'."\n";
$site_map .= '<!-- Last Modified : '.date(DATE_W3C).' -->'."\n";
$site_map .= '<!-- This XML Sitemap is created by Analog Studio -->'."\n";
$site_map .= '<!-- Analog Studio : https://web.analogstd.com/ -->'."\n";
foreach($URLs as $URL){
$site_map .= ' <url>'."\n";
$site_map .= ' <loc>'.preg_replace("/&/", "&", $URL[0]).'</loc>'."\n";
if($URL[1]){
// 最終更新日時が取得できれば<lastmod>に設定する
$site_map .= ' <lastmod>'.$URL[1].'</lastmod>'."\n";
// 普通のファイルなので$freq_setで指定した更新頻度目安を<changefreq>に設定する
$site_map .= ' <changefreq>'.$freq_set.'</changefreq>'."\n";
} else{
// 最終更新日時が取得できなければ<lastmod>に現在の時刻を設定する
$site_map .= ' <lastmod>'.date(DATE_W3C).'</lastmod>'."\n";
// 更新日時が取得できない、つまり動的に生成されるページとなるので<changefreq>に"always"を設定する
$site_map .= ' <changefreq>always</changefreq>'."\n";
}
// 優先度を設定する
// 設定されている階層よりも深い階層には設定の一番最後の優先度を指定する
if($URL[2] < count($priority_set)){
$site_map .= ' <priority>'.$priority_set[$URL[2]].'</priority>'."\n";
} else{
$site_map .= ' <priority>'.end($priority_set).'</priority>'."\n";
}
$site_map .= ' </url>'."\n";
}
$site_map .= '</urlset>';
// 出力ファイルの絶対パスを取得する
$output_path = explode("/", dirname(__FILE__));
if(strpos(OUTPUT, "../") === 0){
$m = substr_count($anchor, "../");
array_splice($output_path, (0 - $m), $m);
$output_path = implode("/", $output_path). str_replace("../", "", OUTPUT);
} else{
$m = explode("/", OUTPUT);
if($m[0] === "." || $m[0] === ""){
array_shift($m);
}
$output_path = dirname(__FILE__). "/". implode("/", $m);
}
echo "\n\n\n$output_path";
file_put_contents($output_path, $site_map, LOCK_EX);
?>
設定
設定はコード内のコメントの通りです。
<アクセス認証>
ここで紹介したスクリプトでは各ページをHTTP通信で取得するので大量のアクセスをするとサーバに大きな負担となってしまいます。
特にページ数が多いサイトでは深刻な問題です。
そこで、簡易的にアクセス制限を入れてあります。
アクセスを許可するキーを用意して GET でキーをスクリプトに渡して認証します。(いわゆるアクセストークン認証)
なので、スクリプト内で設定したキーを渡してアクセスすればサイトマップの生成が実行されます。
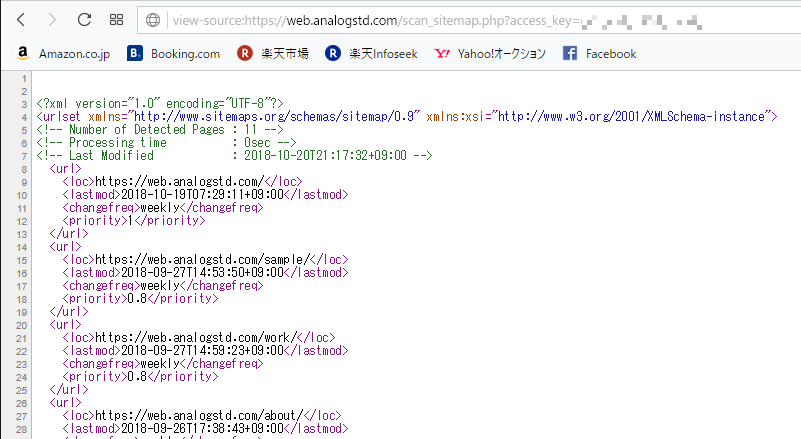
具体的には、以下の URL にアクセスすれば良いです。
URL : [貴方のサイトアドレス]/scan_sitemap.php?access_key=認証用に設定したキー
// 特定のキーをGETで渡して認証する場合
// 認証用のキーは任意の英数字
if($_GET["access_key"] !== "認証用のキー(ランダムな英数字の組み合わせを推奨)"){
exit("Bad Request!!");
}
また、Cron による定期実行をさせる場合に専用サーバであればアクセス元のホスト名や IP アドレスは一意であると思いますので、この情報による認証も入れてあります。
共有サーバでは同じサーバを使っている他の人からのアクセスでも実行できてしまうので注意して下さい。
<TOPページのURLを設定>
TOP ページの URL を設定していきます。
この URL 以下にあるページを検索していくので最上位となるアドレスを入力して下さい。
// トップページのURL
define("HOMEPAGE", "最上位のアドレス ("/"で終わって下さい)");
<出力するファイル名を設定>
出力するファイル名とパスを設定します。
特に拘りがなければ変更する必要はないと思います。
// 出力するサイトマップのファイル名
// ※このPHPファイルから見た相対パスで指定
define("OUTPUT", "出力するサイトマップの相対パス");
<その他の任意設定>
除外する拡張子やファイル名など必要であればコメントを参考に設定して下さい。
不明な点やバグはコメントを頂ければ幸いです。
使い方
まずは、サイトの最上位ディレクトリに上記設定をした “scan_sitemap.php” をアップロードして下さい。
後は “[貴方のサイトアドレス]/scan_sitemap.php?access_key=認証用に設定したキー” にアクセスするだけです。
アクセス方法はブラウザのアドレスバーに打ち込んでも良いですし、wget コマンドなどでアクセスしても良いです。
たまにしか表示されないページの <img> タグなどで呼び出すのも良いです。
XSERVERで自動実行させる (Cronによる定期実行)
最後に Cron による定期実行を設定してみましょう。
共有サーバでは使えるところばかりではないですが、使える場合は自動的にサイトマップの更新ができます。
Xserver では Cron が使えますので、ここでは Xserver での設定方法を紹介します。
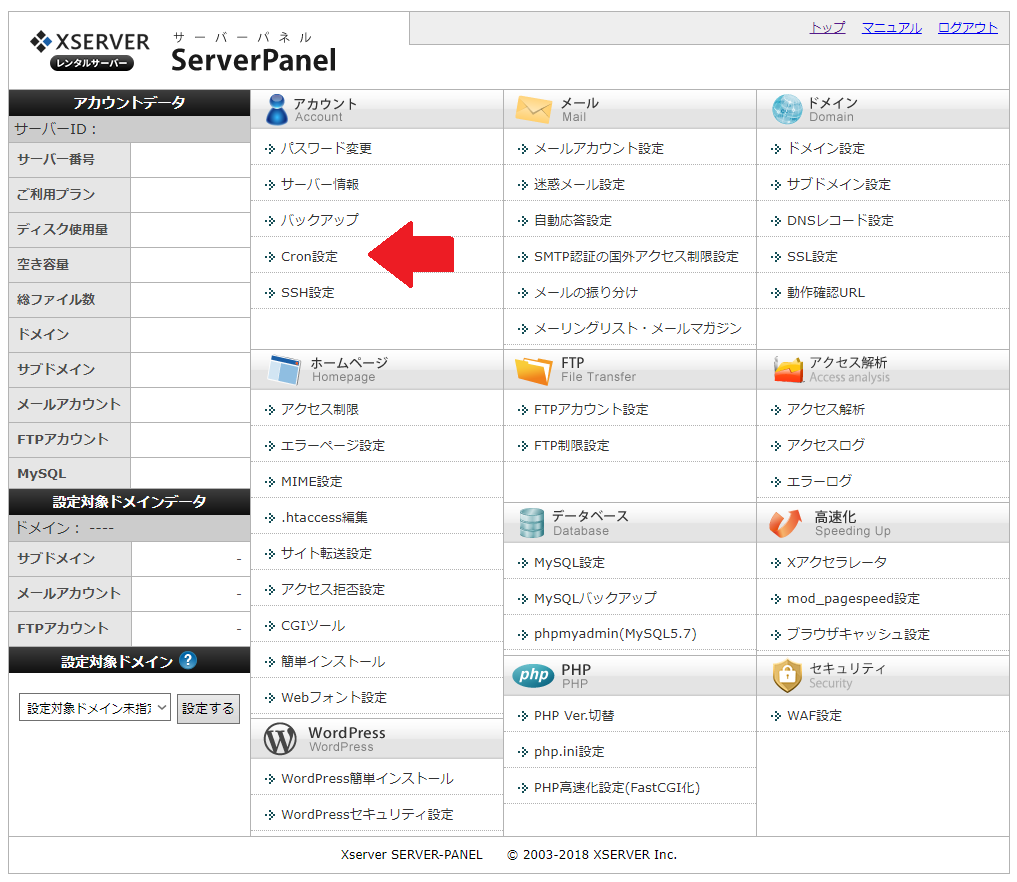
まずは Server Panel にアクセスします。「アカウント」カテゴリ内に「Cron設定」というリンクがあります。
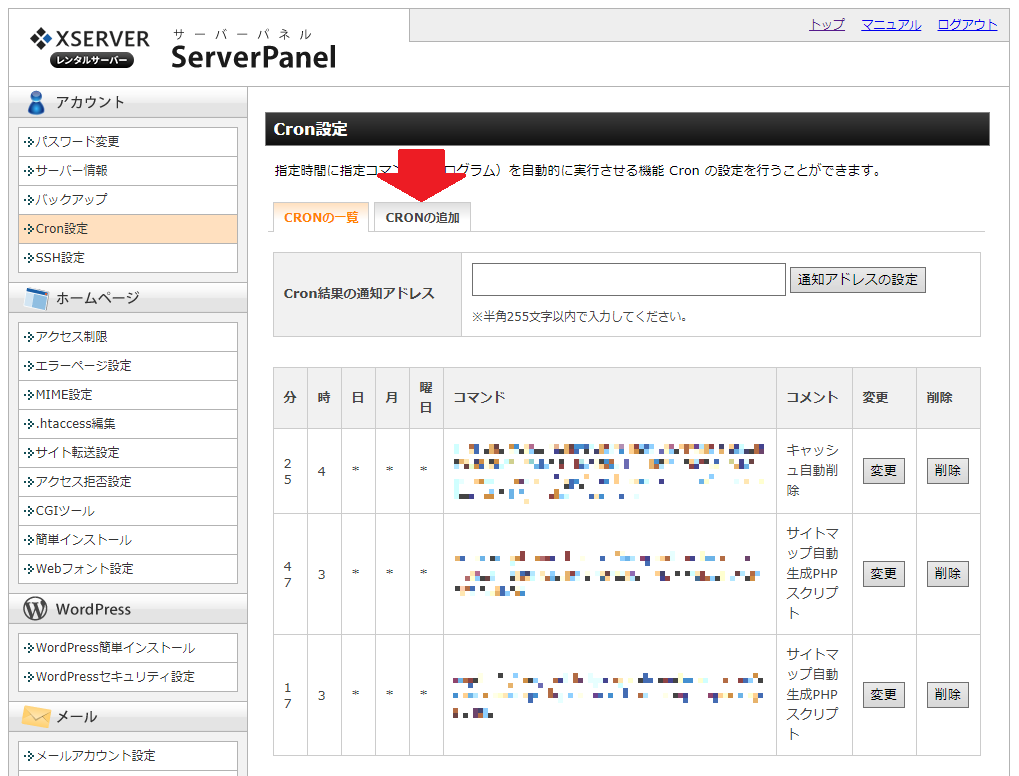
「Cron設定」を開くと Cron に設定されているものが一覧で表示されます。追加する場合は「CRONの追加」をクリックします。
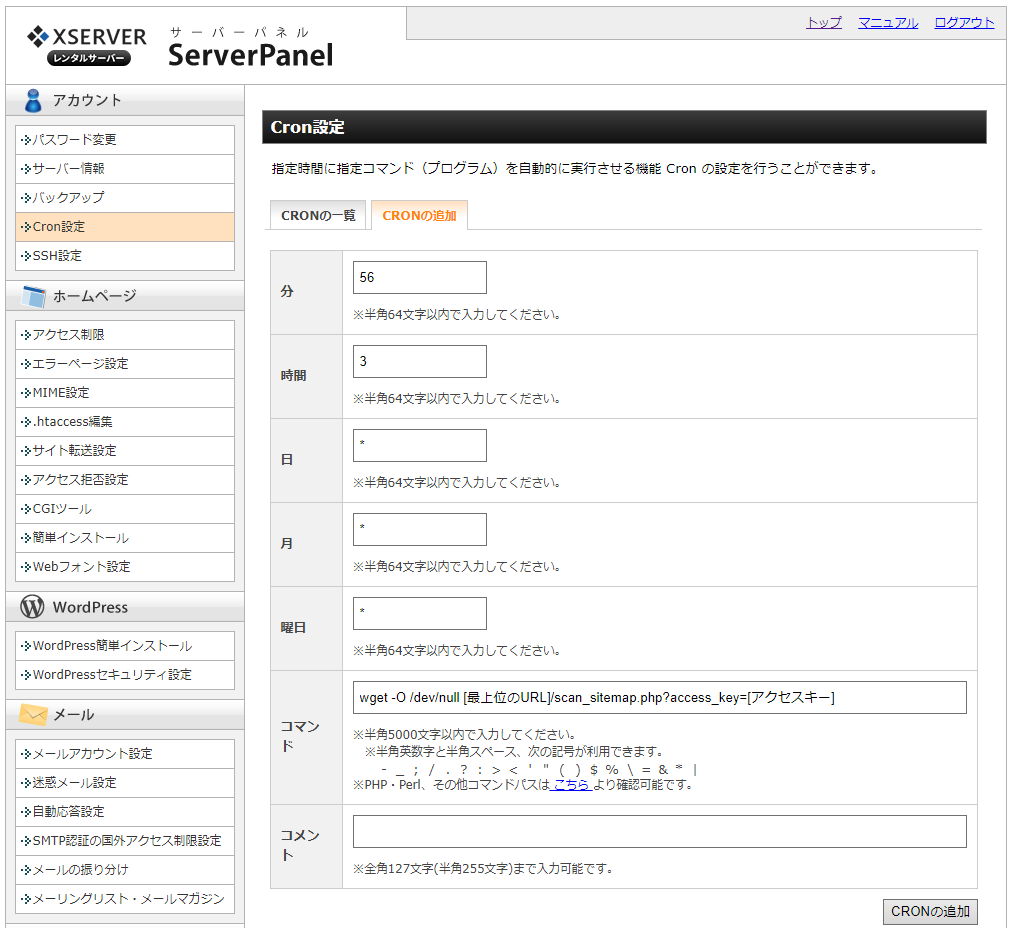
「CRONの追加」を開くと “いつ” “どんな処理” をするか入力できるので、適当に設定します。
時間はどうやら日本時間のようなので深夜の2時~5時ごろのアクセスが少ない時間帯に設定すれば良いと思います。
毎日1回実行したい場合は “日” “月” “曜日” をそれぞれワイルドカード “*” とします。
1週間に1回にしたければ、0~7の数字をどれか1つ設定します。
0と7が日曜日です。
若しくは3文字の略語でも構いません。(例:日曜→sun、水曜→wed)
コマンドには wget コマンドなどで取得してそのまま取得したデータは破棄してしまえばよいです。
(出力先を /dev/null にする Linux では良くやる手法です)
wget -O /dev/null [最上位のURL]/scan_sitemap.php?access_key=[アクセスキー]
これで設定して一覧に表示されれば登録完了です。
あとは時間が来て、サイトマップが生成されればOKです。
まとめ
以上、サイトマップを自動生成するスクリプトの紹介でした。
参考になれば幸いです。
不明な点、おかしな点があればコメント頂ければ対応したいと思います。
コメント
除外するフォルダは、設定出来ますか?
okukunさん
コメントありがとうございます。
この記事を書いた後に必要になって除外ディレクトリを設定できるようにしていましたので、掲載しているコードとZIPファイルを更新しました。
ご確認をお願いします。
以下の設定がありますので、除外したいディレクトリをせってしてみて下さい。
これはすごい…活用させて頂きます!
>kohさん
コメントありがとうございます。お役に立てば幸いです♪
ただ、あまり大きなサイトは想定していないのでサーバの負荷になっていないか生成に掛かった時間を確認するようにして下さい。
※一般的なサーバだとタイムアウト時間が30秒くらいなのでその点にもご注意下さい。
なるほどアドバイスありがとうございます。サイトマップ登録の必要の無い内部リンクを大量に吐き出すページがサイト直下(xxxx.com/xxx.php)にあるのですが
// サイトマップに登録しないディレクトリ名 $ignore_dirs = Array(“/xxx.php/”);で除外できますか?
両側の/はいらないと思います。"xxx.php"で動くと思います。
使ってみて結果がおかしくないか確認してみて下さい。
宜しくお願いします。
お返事ありがとうございます。確かに/はいらないですね、適当にコピペしてたので…xxx.php内のリンクを読んでいないかどうかcronも併せてテストしてみます。ありがとうございました。
一通りテストしてみました。私はこのまま使いますが(いやー助かりました(^_^))いくつか気になる部分があったので一応開発者様へご報告しておきます。
●同階層へのリンクが「directory/」となる場合はトップページのURLが付かず、「https://directory/」などとなります。(「./」で始まるとok?)
このためDreamWeaverのテンプレート機能を使っている場合はサイトルートパス「/directory/」で設定し直すしかないのですがそうすると「https://xyz.com/abc.php」でもalwaysではなく指定した更新頻度となります。これはパラメータが無いので仕様かもしれませんが。
●パラメータ付きのurlをパラメータとして渡している場合(./hoge/?url=http://hoge.net/?a=bbb)(./hoge/?param=http://hoge.net/feed)など、「/」で終わらないリンクが「/」以降をカットしたものとしていないものの2種類が書き出されます。この場合はカットされるとそのurlへアクセスしてもエラーになるのでGoogle的にどうなのかというのはあります。
と言ったところです。ご参考ください。
最後にもう一度 ありがとうございました。
>kohさん
テストありがとうございます。使っていただける方がいるとこのブログの励みになります。
確かに同階層へのリンクの ./ を省略した場合の条件分けがありませんでした。以下の部分を変更すれば良さそうです。
if(strpos($anchor, "..") === 0){ $m = substr_count($anchor, "../") + 1; array_splice($URL_buff, (0 - $m), $m); $next = implode("/", $URL_buff). '/'. preg_replace("/^(\.\.\/)+/", "", $anchor); } else if(strpos($anchor, ".") === 0 || !preg_match("|^https?://|", $anchor)){ $URL_buff[count($URL_buff)-1] = ""; $next = implode("/", $URL_buff). preg_replace("/^\.\//", "", $anchor); } else if(strpos($anchor, HOMEPAGE) === 0){ $next = $anchor; }また、パラメータへのURL等の考慮はしていませんでした。パラメータはパラメータで別に退避させておいて後から付ける方が良さそうです。
バージョンアップなど考えていませんでしたが、機会があればもう少しきれいに、使いやすくしたいと思います。ご指摘ありがとうございました!
なるほど。別のサイト作ってるのでそっち向けにちょっと弄ってみます。あとxmlなのでurlに「&」とか入っているとGoogleがエラーを返してサイトマップファイルを丸ごと敬遠されました(http://kotaroito.hatenablog.com/entry/2015/08/25/150317)。
頂いたものに「htmlspecialchars($URL[0], ENT_QUOTES)」を追記して通りました。ではでは
&のエスケープも参考になりました。こそっと使っているサイトではエスケープ追記します。
ロリポップサーバーで試してみましたが、うまくいきました!シェアありがとうございます。